
Research Intern | Data-Douyin, ByteDance
Period: 04/2025 - Present. Mentor: Dingkang Yang & Xiao Liang

01s | Multi-modal Learning
Xi'an City, Shaanxi
Xi'an Jiaotong University
Origin: Xinxiang City, Henan
I'm currently a final-year master student majored in computer technology at the School of Computer Science and Technology, Xi'an Jiaotong University (XJTU), supervised by Prof. Heli Sun. My research interest lies in deep learning and multi-media computing, primarily focusing on large-scale self-supervised video understanding, multi-modal large langugae models (MLLMs), and misinfo detection (Deepfake & AIGC).
Prior to that, I recevied my B.E. degree (with honors) at the School of Cyber Science and Engineering, Zhengzhou University (ZZU), where I worked closely with Prof. Junxiao Xue (PI, Zhejiang Lab) and Prof. Lei Shi (Vice Dean). Besides, as a student PI, I have led the eMotionAI Lab of Zhengzhou University Students innovative Entrepreneurial Base (North Campus) from 2021 to 2023.
My CSDN Technology Blogs are located at HERE.
Please feel free to contact me if you are interested in my works and want to explore potential collaborations 🙌.
Research Intern | Data-Douyin, ByteDance
Period: 04/2025 - Present. Mentor: Dingkang Yang & Xiao Liang

Research Intern | Multi-modal Evaluation Group, Meituan-M17
Period: 01/2025 - 05/2025. Mentor: Jiaxing Liu & Xiaoyu Li
Member | Data Intelligence and Social Governance Lab, Xi'an Jiaotong University
Period: 09/2023 - Present. Supervisor: Prof. Heli Sun

Visiting Stundent | State Key Laboratory of Communication Content Cognition
Period: 10/2023 - 10/2024. Supervisor: Prof. Heli Sun

Student PI | eMotionAI Lab, Zhengzhou University
Period: 06/2021 - 06/2023. Advisor: Prof. Junxiao Xue
Research Assistant | Machine Vision Lab, Zhengzhou University
Period: 06/2021 - 09/2021. Supervisor: Prof. Jianhong Ma
Research Assistant | Computational Learning Lab, Zhengzhou University
Period: 09/2020 - 06/2023. Supervisor: Prof. Junxiao Xue
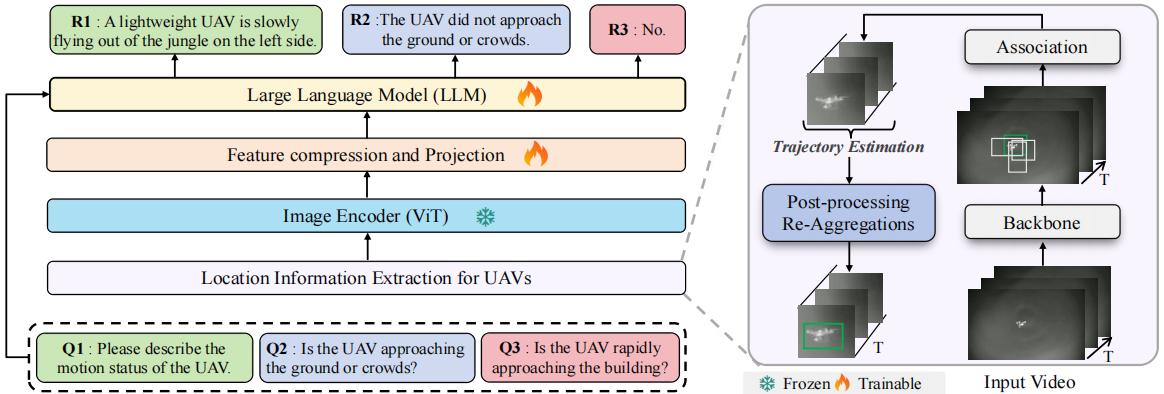
JTD-UAV: MLLM-Enhanced Joint Tracking and Description Framework for Anti-UAV Systems
Yifan Wang*, Jian Zhao*, Zhaoxin Fan†, Xin Zhang, Xuecheng Wu, Yudian Zhang, Lei Jin, Xinyue Li, Gang Wang†, Mengxi Jia, Ping Hu, Zheng Zhu, Xuelong Li
IEEE/CVF CVPR, 2025
[Paper]
Poster
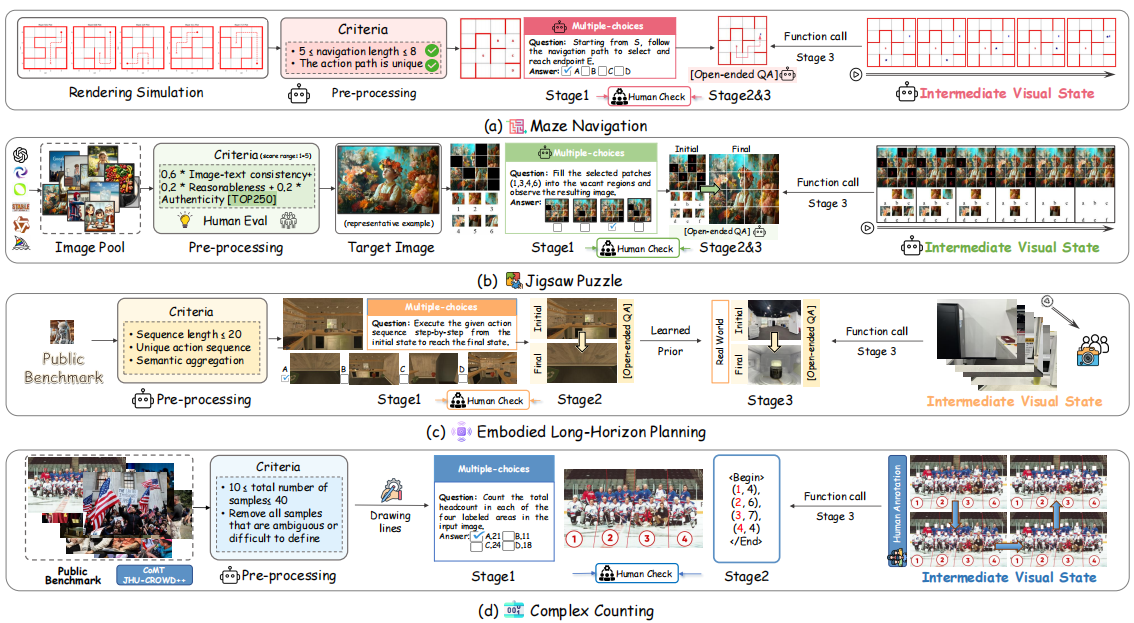
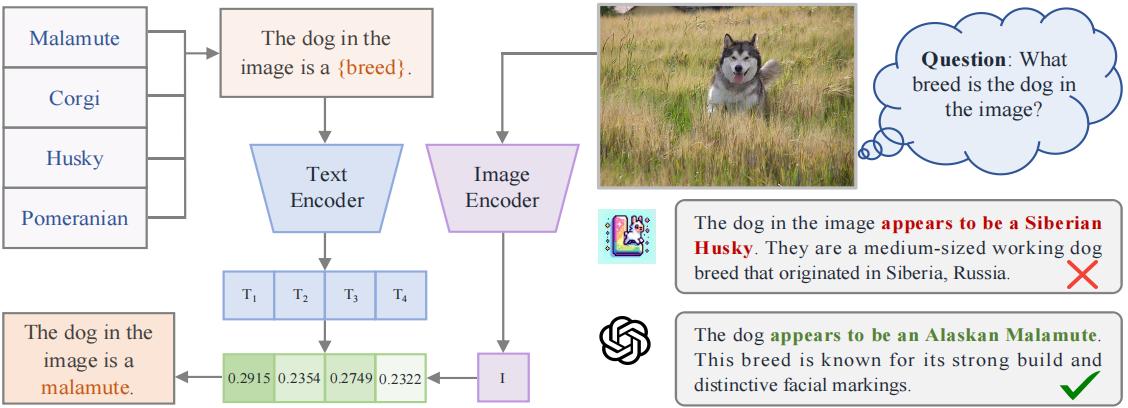
LLaVA-World: Benchmarking and Enhancing Fine-Grained Open-World Knowledge Understanding for MLLMs
Yifan Wang*, Xuecheng Wu*, Yuhao Dong, Zuyan Liu, Jia Zhang, Qi Zhang, Winston Hu, Yongming Rao† (*: Equal Contribution.)
Under Review, 2025
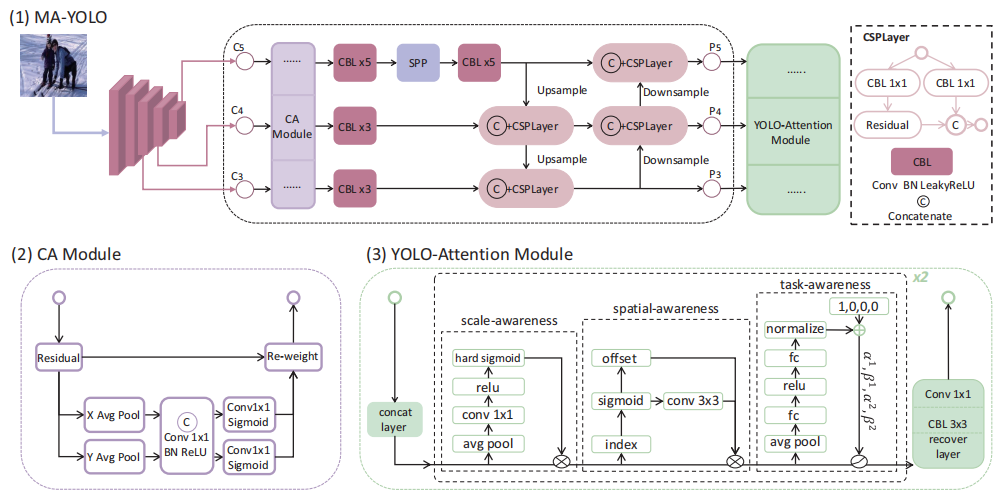
3A-YOLO: New Real-time Object Detectors with Triple Discriminative Awareness and Coordinated Representations
Xuecheng Wu*, Junxiao Xue*†, Liangyu Fu, Jiayu Nie, Danlei Huang, Xinyi Yin
IEEE SMC, 2025
[Paper]
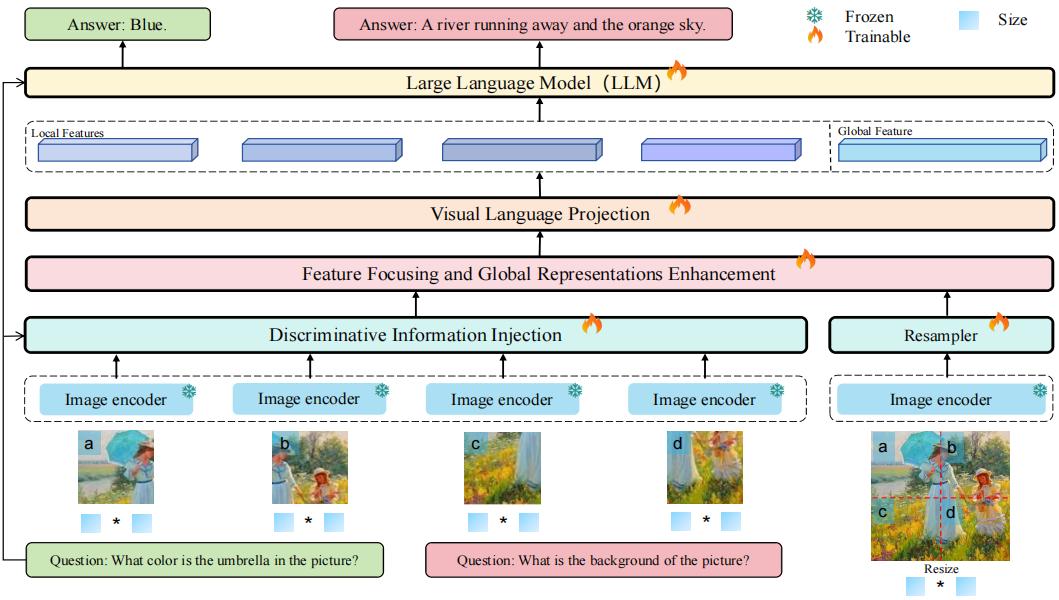
Magnifier: A Pluggable Framework for Enhanced High-Resolution Image Comprehension in Multi-modal Large Language Models
Yifan Wang, Yunfei Wu, Xin Li†, Xuecheng Wu, Wentao Zhang, Haoyu Cao, Yinsong Liu, Deqiang Jiang, Xing Sun, Feiyue Huang†
Under Review, 2025
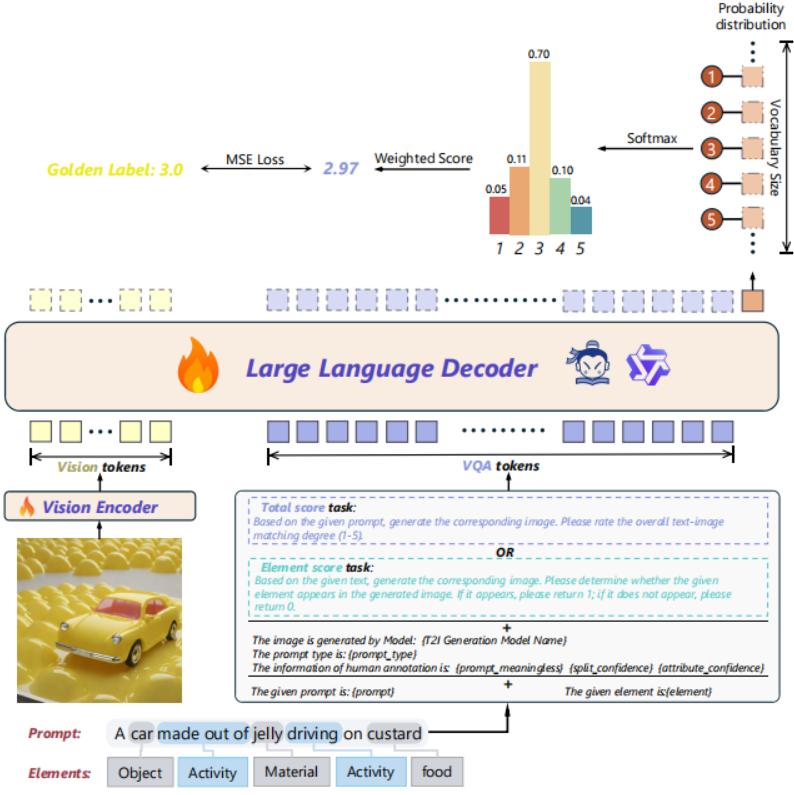
TokenFocus-VQA: Enhancing Text-to-Image Evaluation with Position-Specific Probability Loss and Multi-Perspective Aggregations on LVLMs
Zijian Zhang, Xunhui Zheng, Xuecheng Wu, Chong Peng†, Xuezhi Cao
IEEE/CVF CVPRW, 2025
[Paper]
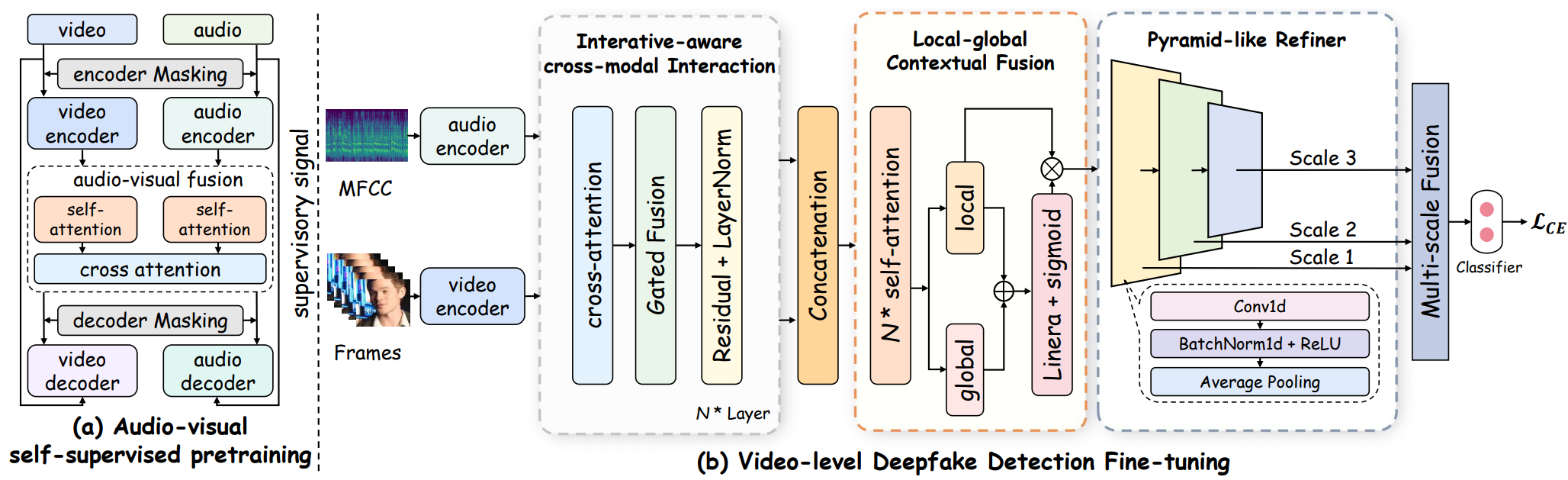
HOLA: Enhancing Audio-visual Deepfake Detection via Hierarchical Contextual Aggregations and Efficient Pre-training
Xuecheng Wu, Heli Sun†, Danlei Huang, Xinyi Yin, Yifan Wang, Hao Wang, Jia Zhang, Fei Wang, Peihao Guo, Suyu Xing, Junxiao Xue, Liang He
ACM MM, 2025
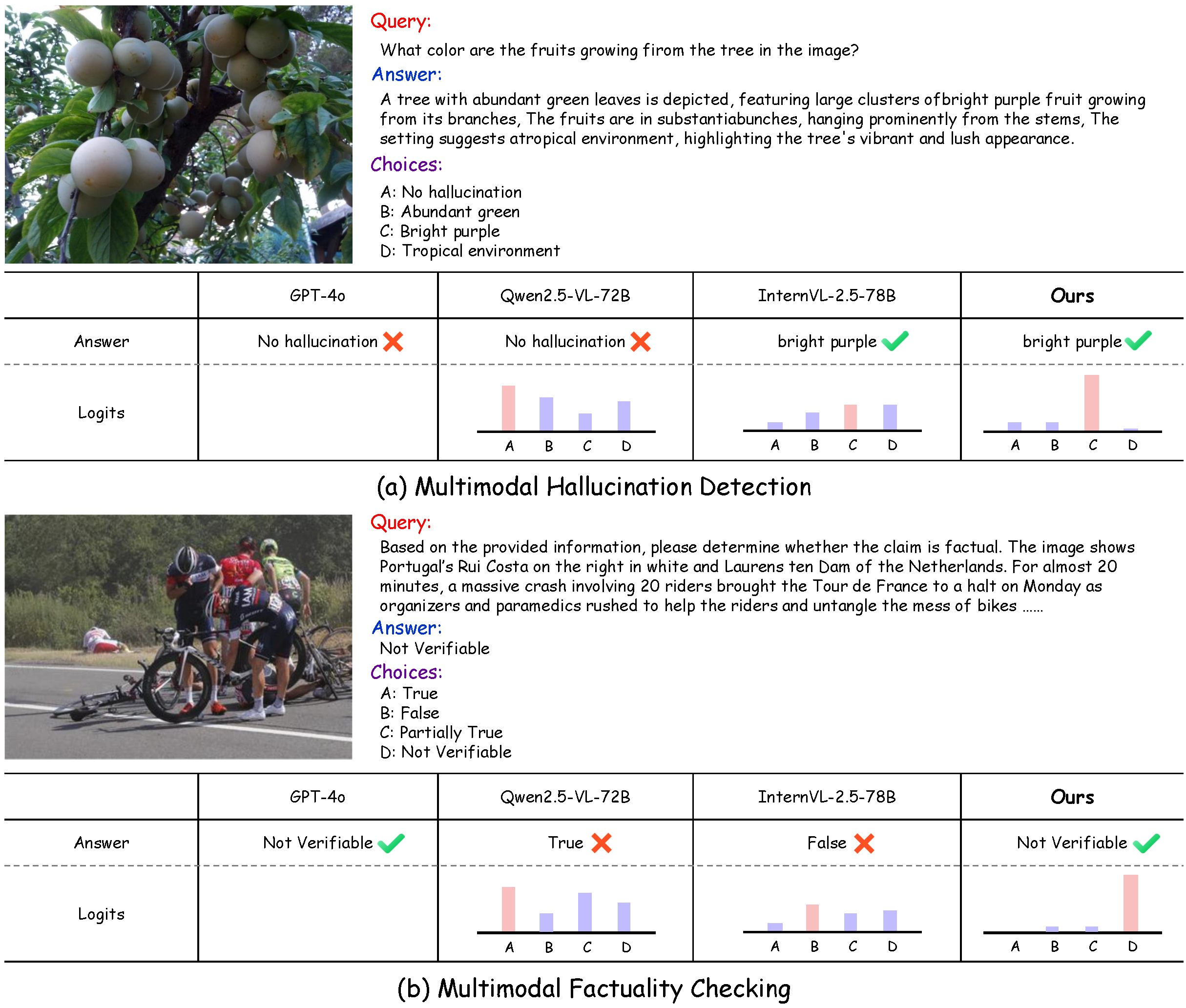
HKD4VLM: A Progressive Hybrid Knowledge Distillation Framework for Robust Multimodal Hallucination and Factuality Detection in VLMs
Zijian Zhang*, Xuecheng Wu*, Danlei Huang, Siyu Yan, Chong Peng†, Xuezhi Cao (*: Equal Contribution.)
ACM MM, 2025
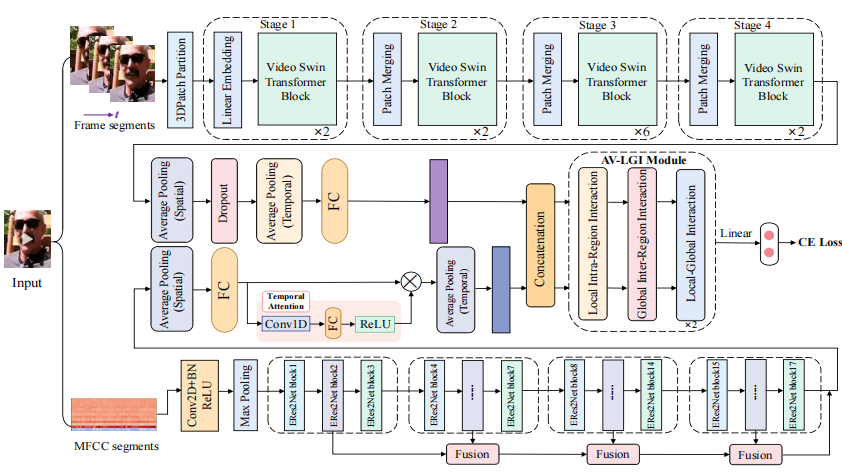
Building Robust Video-Level Deepfake Detection via Audio-Visual Local-Global Interactions
Yifan Wang*, Xuecheng Wu*, Jia Zhang, Mohan Jing, Keda Lu, Jun Yu†, Wen Su, Fang Gao, Qingsong Liu, Jianqing Sun, Jiaen Liang (*: Equal Contribution and Radom Order.)
ACM International Conference on Multimedia (MM), 2024
[Paper]
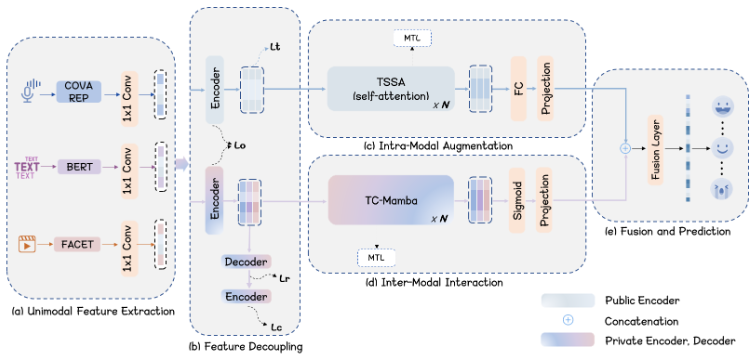
DDSE: A Decoupled Dual-Stream Enhanced Framework for Multimodal Sentiment Analysis with Text-Centric SSM
Shenjie Jiang, Zhuoyu Wang, Xuecheng Wu, Hongru Ji, Mingxin Li, Xianghua Li, Chao Gao
ACM MM, 2025
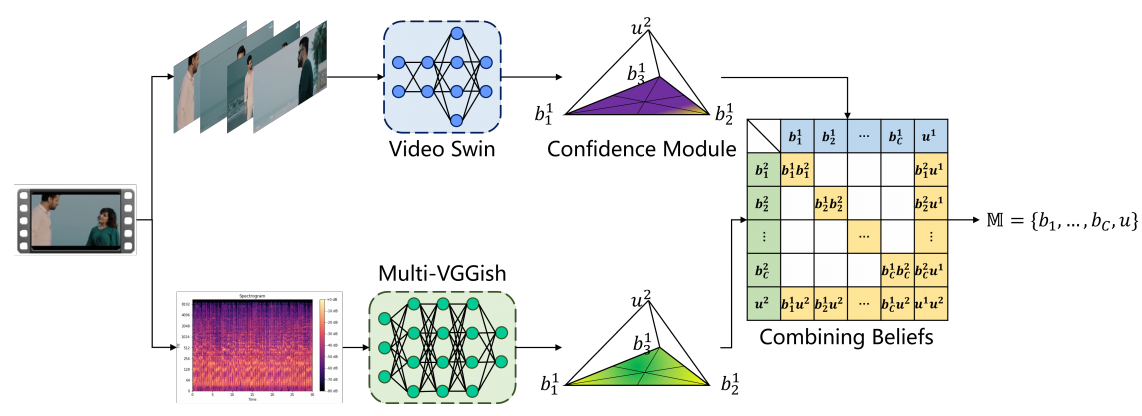
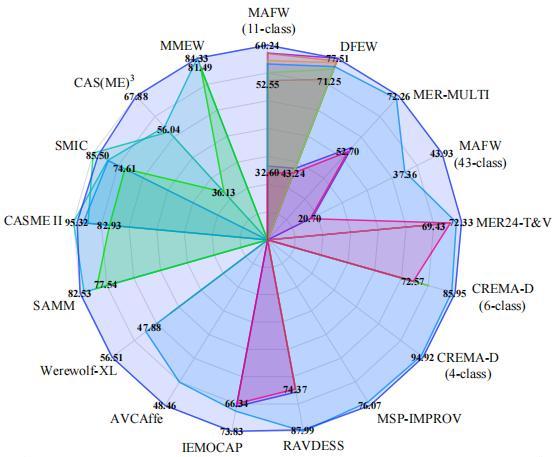
A Trustworthy Method for Multimodal Emotion Recognition
Junxiao Xue, Xiaozhen Liu†, Jie Wang, Xuecheng Wu, Bin Wu
Big Data Mining and Analytics, 2025
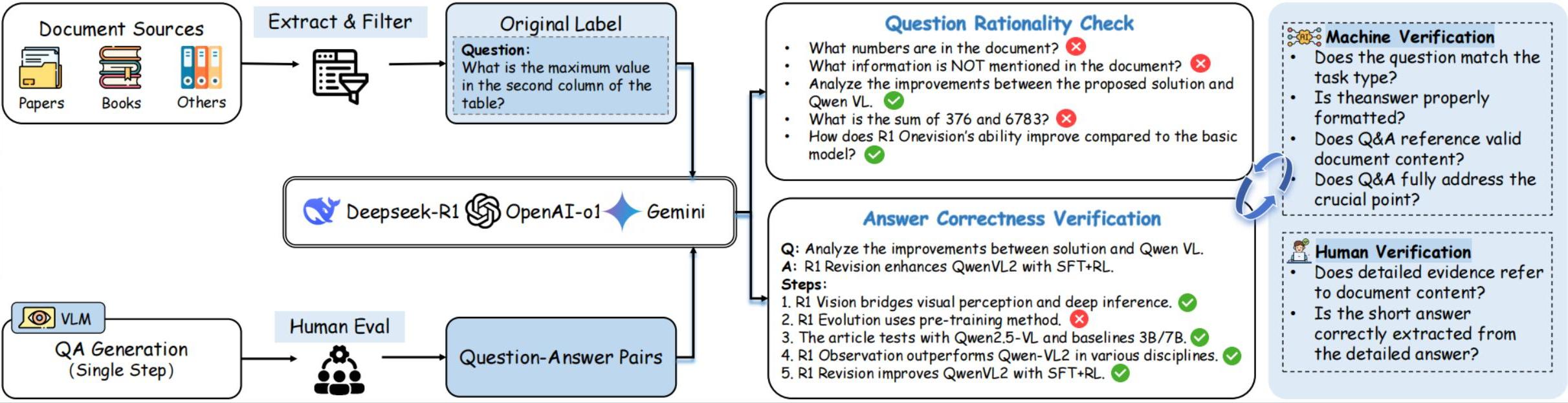
LR-Doc: Benchmarking and Advancing Long Document Reasoning in MLLMs with Learned Priors
Yifan Wang*, Xuecheng Wu*, Danlei Huang, Zhaoxin Fan†, Xinyi Yin, Tingqi Hu, Yang Xiao, Zhe Gao, Jun Xie, Xin Fu, Liang Xie†
Under Review, 2025
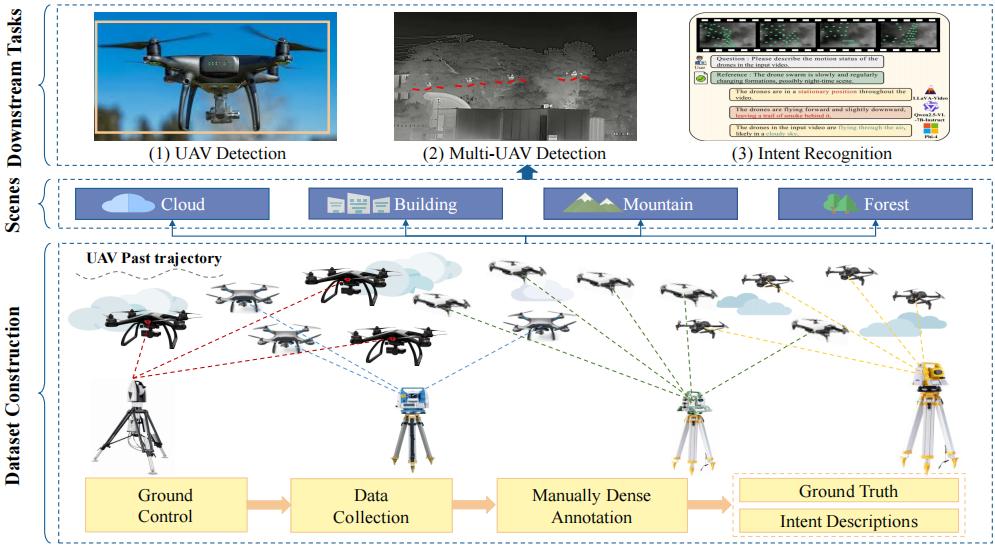
MM-AntiUAV: A Comprehensive Benchmark for Multi-UAV Tracking and Intent Recognition
Yifan Wang*, Jian Zhao*, Xuecheng Wu, Xin Zhang, Danlei Huang, Zhaoxin Fan†, Gang Wang†, Lei Jin, Jianan Li, Xuelong Li
Under Review, 2025
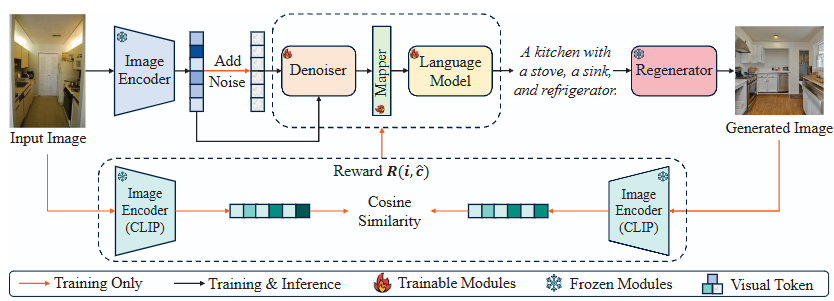
DSACap: Enhancing Visual-Semantic Alignment with Diffusion-based Framework for Image Captioning
Liangyu Fu, Junbo Wang, Yuke Li, Qiangguo Jin, Hongsong Wang, Ya Jing, Linjiang Huang, Liang Yao, Jiangbin Zheng, Xuecheng Wu, Zhiyong Wang
ACM MM, 2025
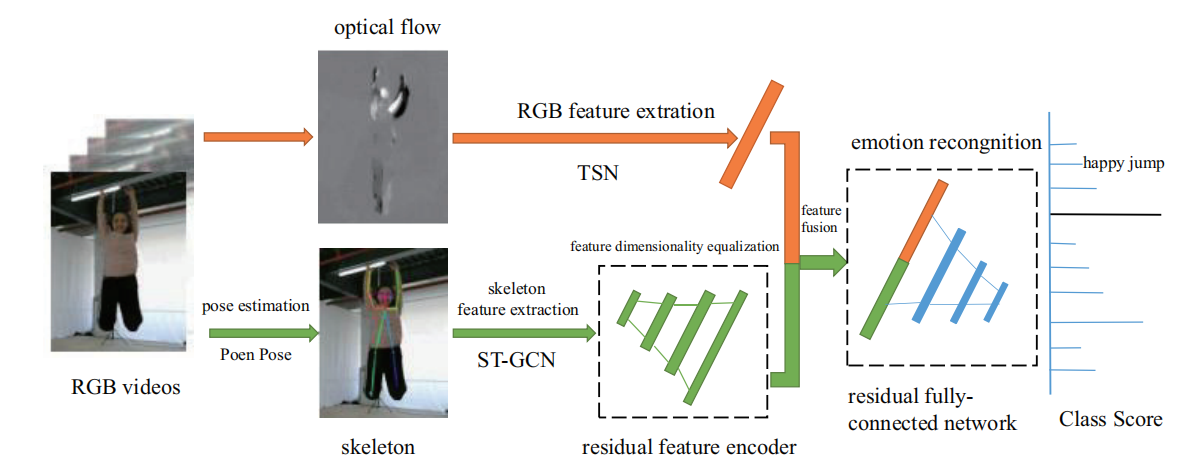
Affective Video Content Analysis: Decade Review and New Perspectives
Junxiao Xue, Jie Wang†, Xiaozhen Liu, Qian Zhang, Xuecheng Wu
Big Data Mining and Analytics,2024
[Paper]
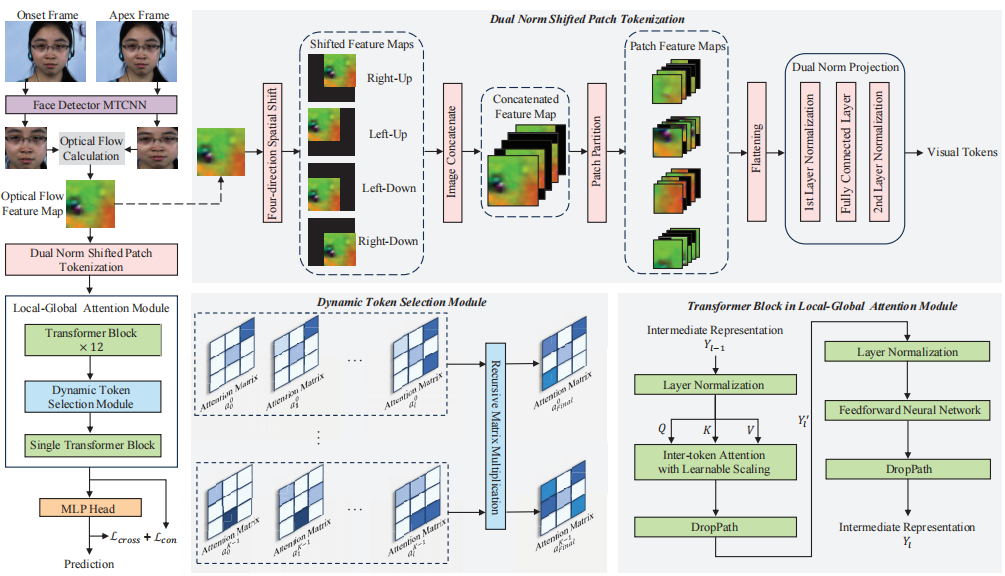
PTSR: A Unified Patch Tokenization, Selection and Representation Framework for Efficient Micro-expression Recognition
Liangyu Fu, Junbo Wang, Qiangguo Jin, Yining Zhu, Hongsong Wang, Yuke Li, Xuecheng Wu, Zhiyong Wang†
ACM ICMR, 2025
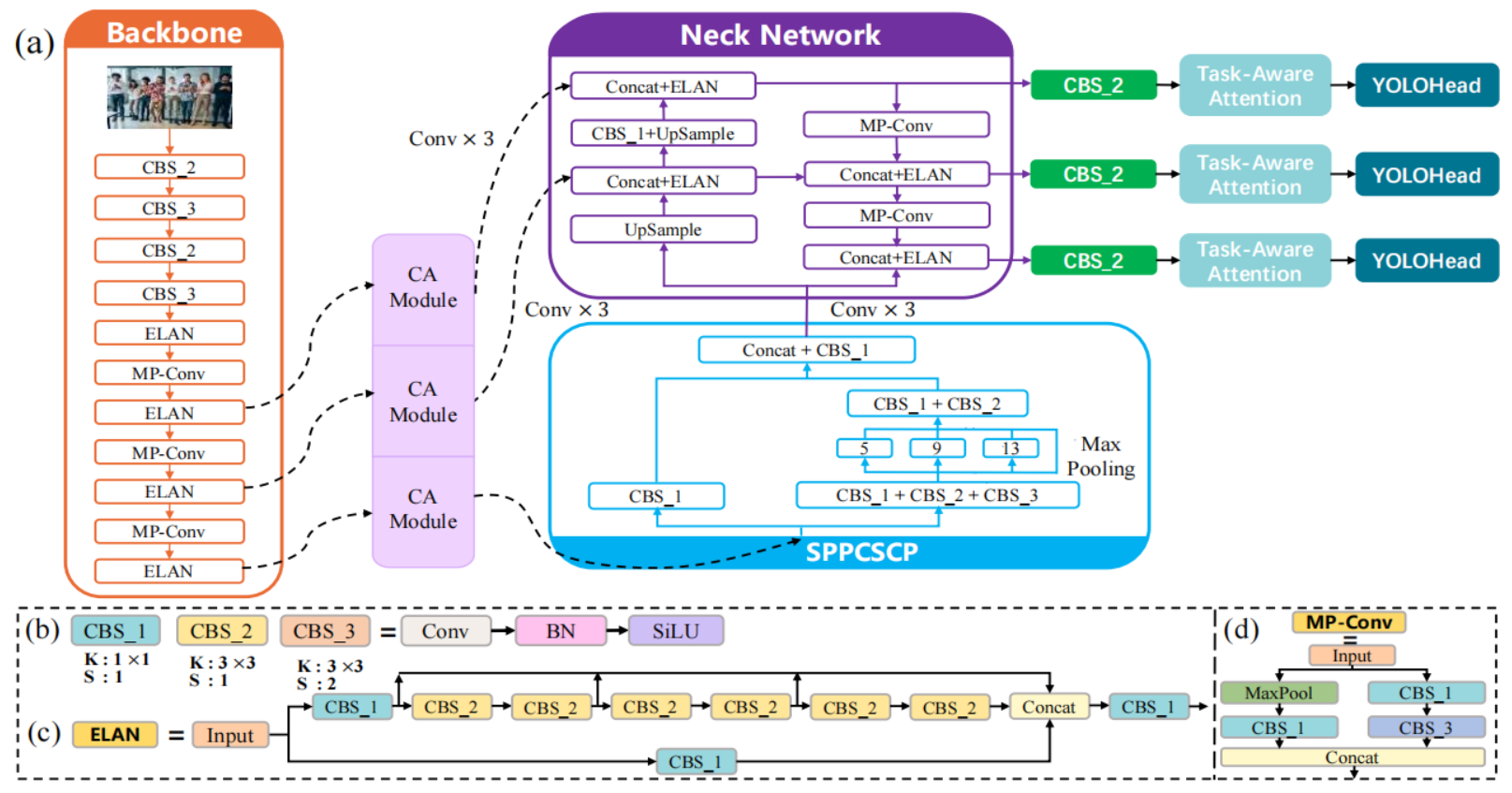
TACR-YOLO: A Real-time Detection Framework for Abnormal Human Behaviors Enhanced with Coordinate and Task-Aware Representations
Xinyi Yin, Wenbo Yuan, Xuecheng Wu†, Liangyu Fu, Danlei Huang
IJCNN, 2025
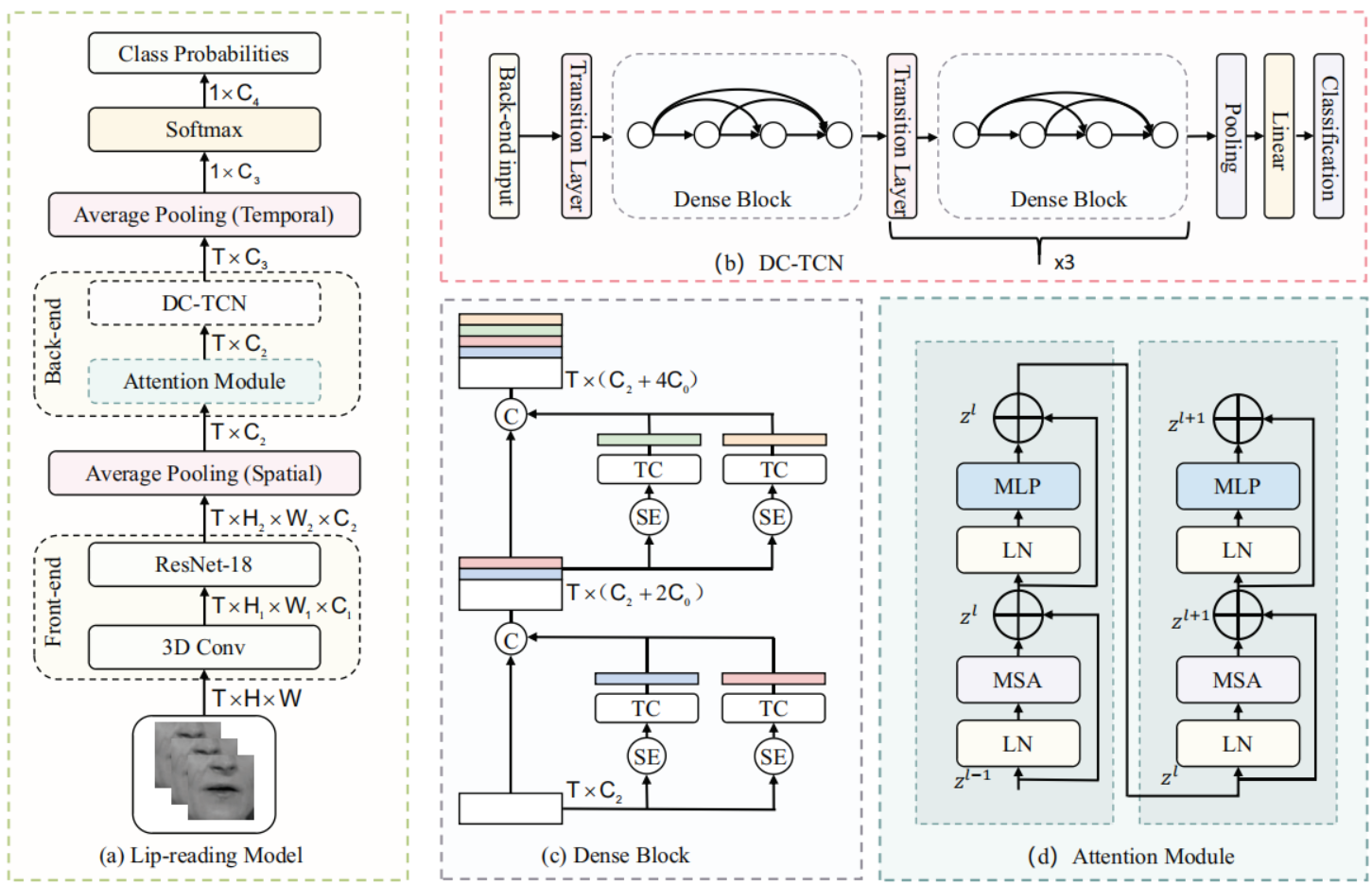
InfoSyncNet: Information Synchronization Temporal Convolutional Network for Visual Speech Recognition
Junxiao Xue, Xiaozhen Liu†, Xuecheng Wu, Fei Yu, Jun Wang
IJCNN, 2025
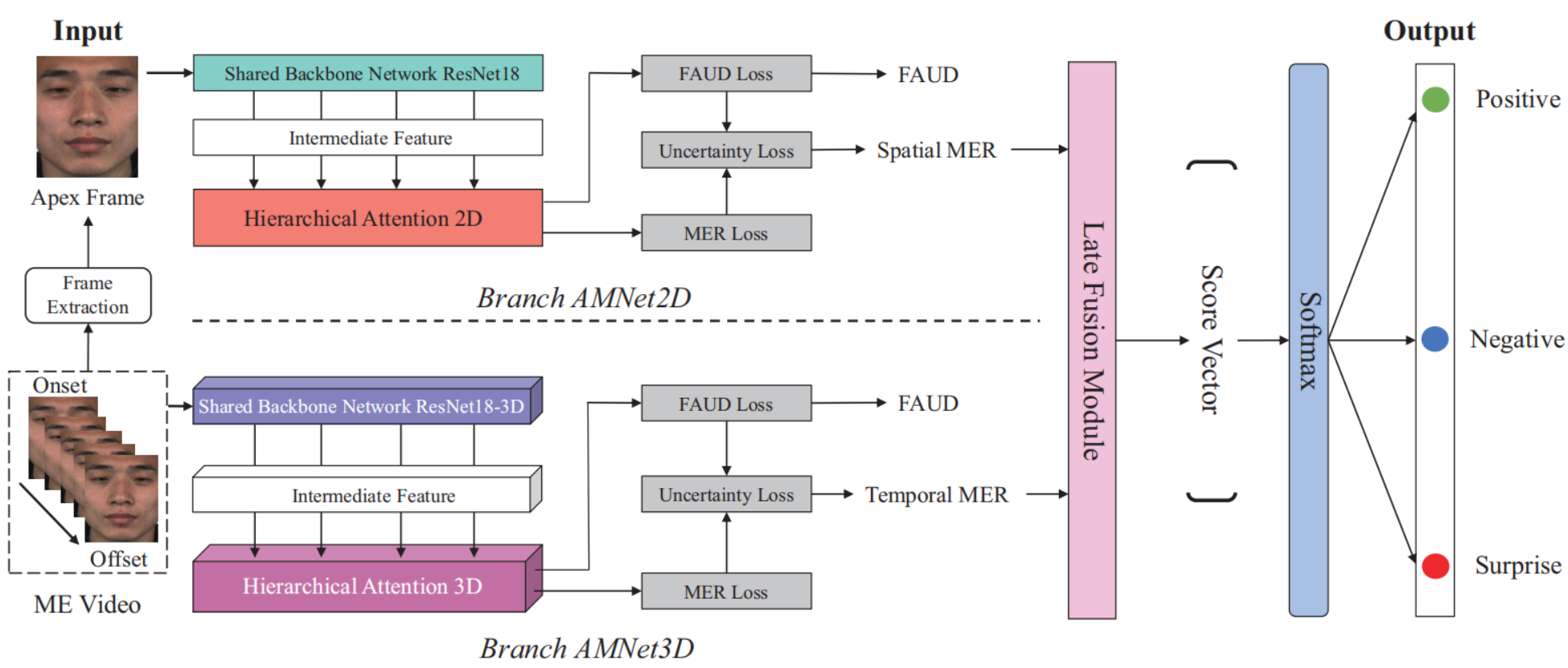
FAMNet: Integrating 2D and 3D Features for Micro-expression Recognition via Multi-task Learning and Hierarchical Attention
Liangyu Fu, Xuecheng Wu†, Danlei Huang, Xinyi Yin
IJCNN, 2025
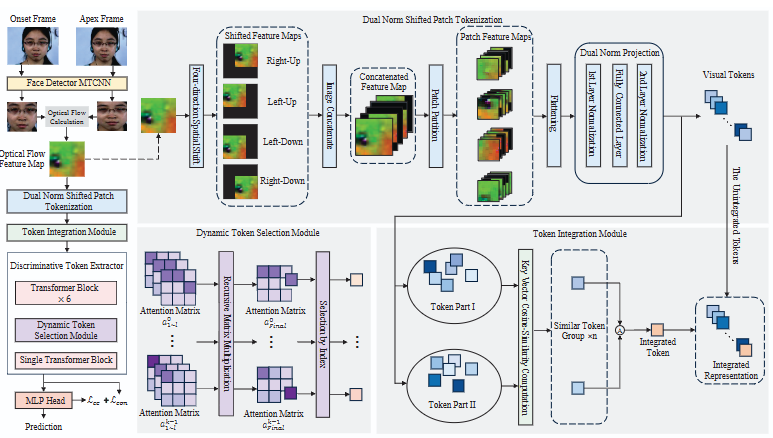
EPIR: An Efficient Patch Tokenization, Integration and Representation Framework for Micro-expression Recognition
Liangyu Fu, Junbo Wang, Yuke Li, Yining Zhu, Hongsong Wang, Xuecheng Wu, Kun Hu
IEEE TCSVT'25, Under Review
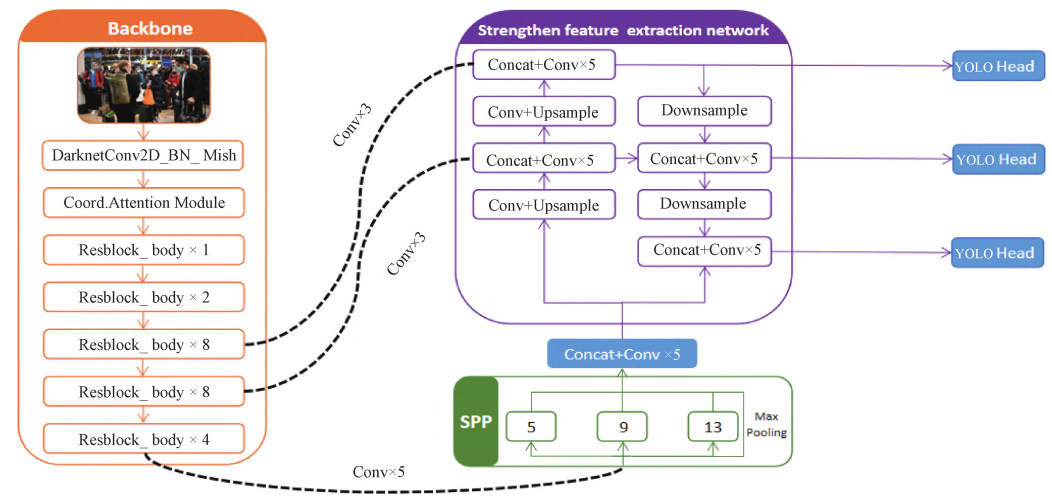
A Method on Mask Wearing Detection of Natural Population Based on Improved YOLOv4
Junxiao Xue*, Xuecheng Wu*, Shihao Wang, Mengmeng Tian, Lei Shi†
Journal of Zhengzhou University (Engineering Science), 2022
[Paper]
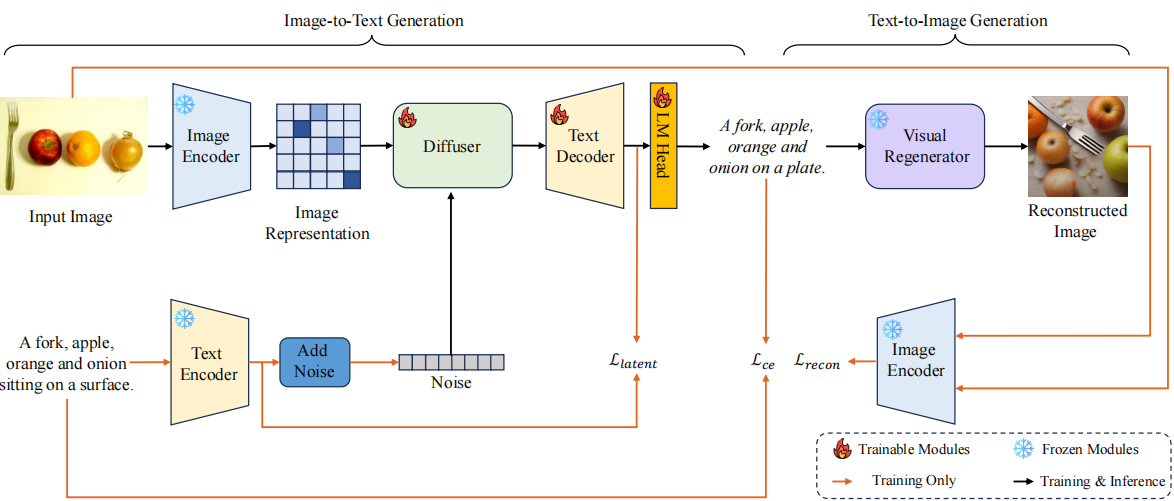
MirrorDiff: Learning Mirror Diffusion for Image Captioning via Regeneration
Junbo Wang, Liangyu Fu, Yining Zhu, Qiangguo Jin, Hongsong Wang, Yuke Li, Xuecheng Wu, Kun Hu†
ACM ICMR, 2025
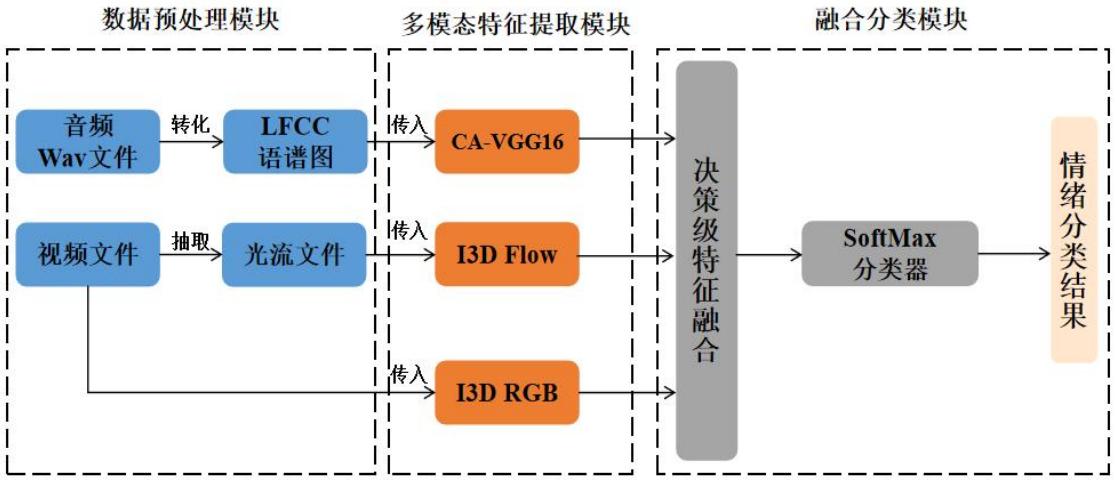
ICVNet: A Method on Cross-modal Fusion of Short Video Emotion Recognition
Junxiao Xue*, Xuecheng Wu*, Qian Zhang, Mengmeng Tian, Lanhang Zhai, Lei Shi†
Chinese Journal of Ergonomics, 2022
[Paper]